Archive
Zanran – a new data search engine
I’ve been playing with a new data search engine called Zanran – that focuses on finding numerical and graphical data. The site is in an early beta. Nevertheless my initial tests brought up material that would only have been found using an advanced search on Google – if you were lucky. As such, Zanran promises to be a great addition for advanced data searching.

Zanran.com - Front Page
Zanran focuses on finding what it calls ‘semi-structured’ data on the web. This is defined as numerical data presented as graphs, tables and charts – and these could be held in a graph image or table in an HTML file, as part of a PDF report, or in an Excel spreadsheet. This is the key differentiator – essentially, Zanran is not looking for text but for formatted numerical data.
When I first started looking at the site I was expecting something similar to Wolfram Alpha – or perhaps something from Google (e.g. Google Squared or Google Public Data). Zanran is nothing like these – and so brings something new to search. Rather than take data and structure or tabulate it (as with Wolfram Alpha and Google Squared), Zanran searches for data that is already in tables or charts and uses this in its results listing.

Zanran.com Search: "Average Marriage Age"
The site has a nice touch in that hovering the cursor over results gives you the relevant data page – whether a table, a chart or a mix of text, tables or charts.

Zanran.com - Hovering over a result brings up an image of the data.
The advanced search options allow country searching (based on server location), document date and file type, each selectable from a drop-down box, as well as searches on specified web-sites. At the moment only English speaking countries can be selected (Australia, Canada, Ireland, India, UK New Zealand, USA and South Africa). The date selections allow for the last 6, 12 or 24 months and the file type allows for selection based on PDF; Excel; images in HTML files; tables in HTML files; PDF, Excel and dynamic data; and dynamic data alone. PowerPoint and Word files are promised as future options. There are currently no field search options (e.g. title searches).
My main dislike was that the site doesn’t give the full URLs for the data presented. The top-level domain is given, but not the actual URL which makes the site difficult to use when full attribution is required for any data found (especially if data gets downloaded, rather than opening up in a new page or tab).
Zanran.com has been in development since at least 2009 when it was a finalist in the London Technology Fund Competition. The technology behind Zanran is patented and based on open-source software, and cloud storage. Rather than searching for text, Zanran searches for numerical content, and then classifies it by whether it’s a table or a chart.
Atypically, Zanran is not a Californian Silicon Valley Startup, but is based in the Islington area of London, in a quiet residential side-street made up of a mixture of small mostly home-based businesses and flats/apartments. Zanran was founded by two chemists, Jonathan Goldhill and Yves Dassas, who had previously run telecom businesses (High Track Communications Ltd and Bikebug Radio Technologies) from the same address. Funding has come from the London Development Agency and First Capital among other investors.
Zanran views competitors as Wolfram Alpha, Google Public Data and also Infochimps (a database repository – enabling users to search for and download a wide variety of databases). The competitor list comes from Google’s cache of Zanran’s Wikipedia page as unfortunately, Wikipedia has deleted the actual page – claiming that the site is “too new to know if it will or will not ever be notable“.

Google Cache of Zanran's Wikipedia entry
I hope that Wikipedia is wrong and that Zanran will become “notable” as I think the company offers a new approach to searching the web for data. It will never replace Google or Bing – but that’s not its aim. Zanran aims to be a niche tool that will probably only ever be used by search experts. However as such, it deserves a chance, and if its revenue model (I’m assuming that there is one) works, it deserves success.
RIP Kartoo
Many searchers depend on their bookmark list but what happens when a key site disappears: if you don’t know how to search you are stuck.
Searching isn’t just going to google and typing your query in the search box. Expert searching demands that you consider where the information you are looking for is likely to be held, and in what format. It requires the searcher to understand the search tools they use – how they work and their strengths and weaknesses. Such skills are crucial when key sites disappear as happened in January with the small French meta-search engine, Kartoo.
Kartoo was innovative and presented results graphically. It enabled you to see links between terms and was brilliant for concept searching where you didn’t really know where to start. Unfortunately it’s now gone to cyber-heaven, or wherever dead web-sites disappear to. It will be missed – at least until something similar appears. Already Google’s wonderwheel (found from the “options” link just above the search results”) offers some of the functionality and graphic feel, and there are other sites that offer similar capabilities (e.g. Touchgraph). Kartoo however was special – it was simple, free and showed that Europeans can still come up with good search ideas.
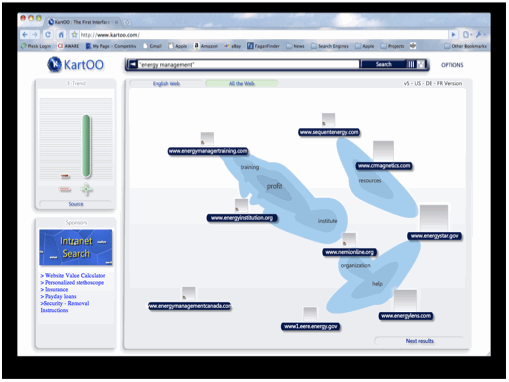
Of course Kartoo isn’t the first innovative site to disappear. Over the years, many great search tools have gone. Greg Notess lists some in his SearchEngineShowdown blog – and an article in Online magazine. There are more. How many people remember IIBM’s Infomarket service – an early online news aggregator from 1995, or Transium.
In fact, it was learning that sites are mortal that led to my approach to searching: don’t depend on a limited selection of sites but rather know how to find sites and databases that lead you to the information wanted. That’s a key skill for all researchers and is as valid today in the Google generation as it was in the days before Google.
Yauba – Big Brother isn’t watching you
Sixty years after George Orwell published 1984 many of the ideas have, unfortunately, become commonplace. There are speed cameras watching how fast you drive, and CCTV monitoring many UK towns. On the Internet, search engines such as Google monitor your searches – keeping the data for months. They know what operating system you use. AWARE doesn’t record this information, despite showing some in our top bar, but many sites, and most search engines do).
Yauba bucks the trend by proudly announcing that it respects user privacy. Its privacy policy proudly states:
Following the Iranian elections (June 2009) many Iranian dissidents and protesters have switched to Yauba, according to the searchengine blog site, Pandia.
“Ahmed Hossain, CIO of Yauba, tells Pandia: “Our traffic from Iran has jumped 300% over the past several days, as many of them are using the Yauba Search Engine and the anonymity proxy filter to access blocked sites and get news from foreign sources.”
Anonymity may be important for some people. However for most, it’s search results that count. Although Yauba claims to be able to search semantically, differentiating between Java the island, Java the coffee and Java the computer language is this a meaningless boast?
In other words is Yauba worth using for those not looking to hide their identity.
The short answer is yes. Yauba searches various types of content – which are separated. As such it enables you to quickly find Acrobat files, Word documents, PowerPoint presentations, news, blogs, images, video, etc. in a single search. Each are kept distinct – and this is an interesting differentiator between it and other search engines. It also presents ways of refining queries and where there are alternative meanings it shows these – allowing users to pick the one they want.
Rather than use the search they suggest i.e. Java I put in Apple. The three meanings I thought of were
- The fruit
- The computer company
- The music company founded by the Beatles
In fact, there are several more – as Yauba shows:
apple can mean:
Apple Inc. (formerly Apple Computer, Inc.), a consumer electronics and software company Apple Bank, an American bank in the New York City area Apple Corps, a multimedia corporation founded by The Beatles Apple (album), an album by Mother Love Bone Apple (band), a British psychedelic rock band Apple Records, record label founded by The Beatles Apple I, Apple II series, Apple III, etc., various personal computer models produced by Apple, Inc and sold from 1976 until 1992. Ariane Passenger Payload Experiment, an Indian experimental communication satellite launched in 1981 Apple (automobile), an American automobile manufactured by Apple Automobile Company from 1917 to 1918 Billy Apple, artist Fiona Apple, a Grammy award winning American singer-songwriter R. W. Apple, Jr., an associate editor at The New York Times
Clicking on Apple (automobile) gives a number of results – not all directly relevant but some which were. There is also a brief encyclopedia type entry at the top of the page:
The Apple was a short-lived American automobile manufactured by Apple Automobile Company in Dayton, Ohio from 1917 to 1918. Agents were assured that its $1150 Apple 8 model was “a car which you can sell!”. Sadly for the company, it would seem that the public did not buy.

On the right of the screen are various suggestions for alternative searches. For example, a search for apple gives:
Compare the clarity of this to the same search on google. (Admitedly the search is not sophisticated and a competent searcher would refine the term – but for testing, it’s good enough)
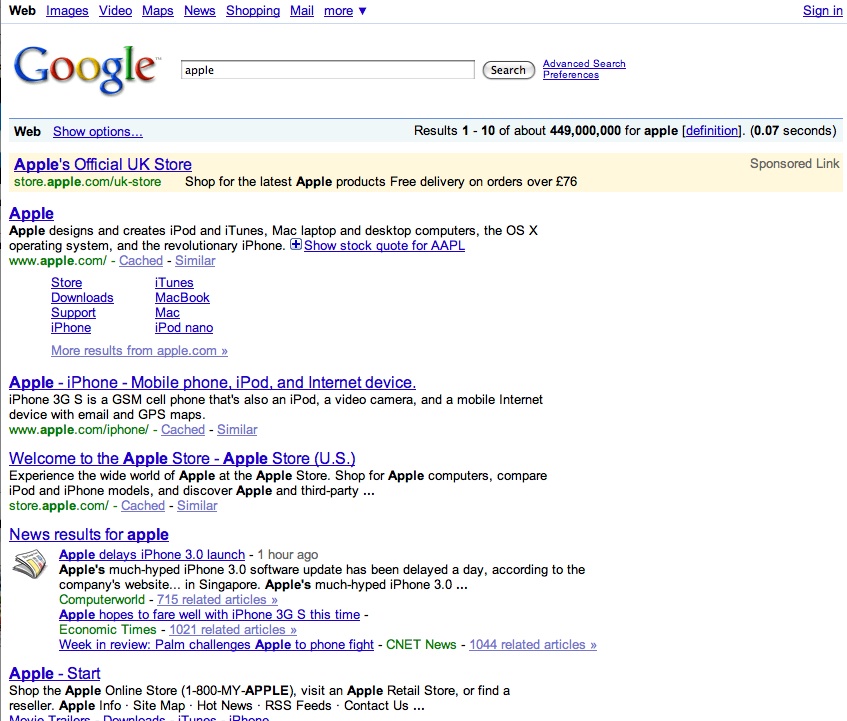
It means that amateur searchers are more likely to find resuls for complex searches – fulfilling Yauba’s claim to allow people to search without a knowledge of Boolean logic.
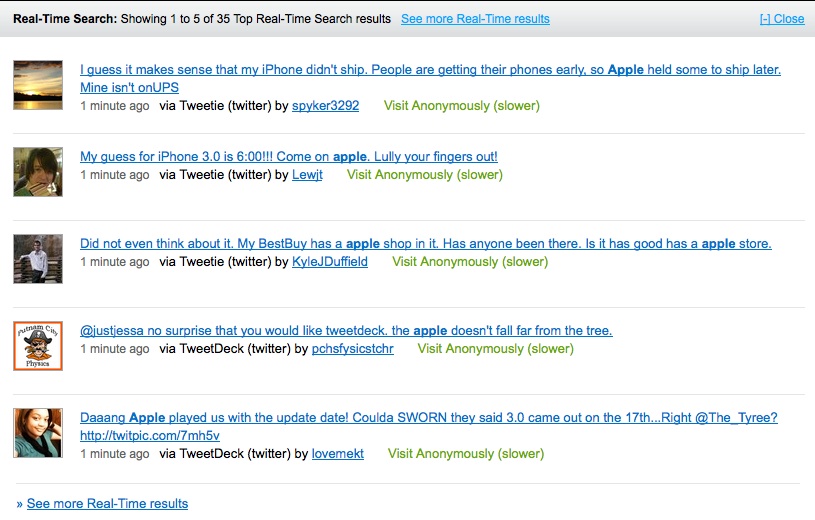
Also interesting is that a component of each search includes a real-time element – from Twitter and social news from Digg. The real time search element is useful as it provides another option to scoopler.
Sponsored ads appear to come from the Google network. There are also options to filter searches (although there is currently no information on what is being filtered) and a Lite version which seems to remove the refinement options and the top-level definitions (i.e. making it more Google like in its results presentation).
There is also an option to refine searches – alongside the search box.
 Selection of one of the options allows further search refinement either by keyword
Selection of one of the options allows further search refinement either by keyword
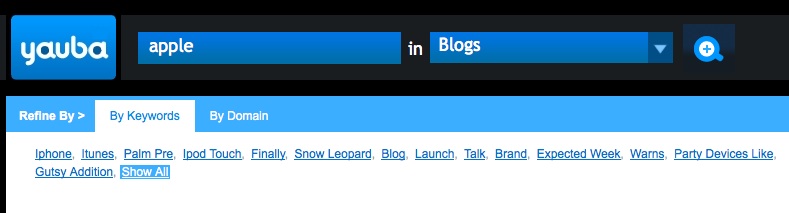 or domain
or domain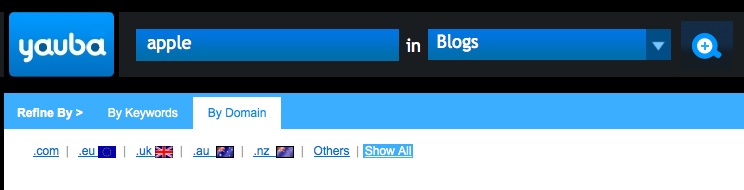
Overall I like Yauba. The interface is clean (and the black background makes a change from competitors).
Currently the site says it’s only an early Beta / Late Alpha preview release so more work / changes can be expected. Hopefully these will include Help files explaining what the Lite search is supposed to do and what a Filtered search actually filters. Also, what syntax is acceptable – to refine searches. Does Boolean searching actually work, for example? On my brief tests it seemed to – as did phrase searching i.e. putting search terms in quotes. What about other options – could any of the advanced search options from Exalead be included. And will the site cover more countries, than the current small number (Italy, France, UK, India, Brazil, Russia and the .com site)? Yauba promises to cover more countries – I’m just surprised that there is no Chinese or German version as I would have expected these before the Italian version. I guess the Yauba team have Italian speakers but currently no Chinese speakers.

Go to AWARE's web-site





 Competitive Intelligence News
Competitive Intelligence News
- An error has occurred; the feed is probably down. Try again later.
