Archive
Yauba – Big Brother isn’t watching you
Sixty years after George Orwell published 1984 many of the ideas have, unfortunately, become commonplace. There are speed cameras watching how fast you drive, and CCTV monitoring many UK towns. On the Internet, search engines such as Google monitor your searches – keeping the data for months. They know what operating system you use. AWARE doesn’t record this information, despite showing some in our top bar, but many sites, and most search engines do).
Yauba bucks the trend by proudly announcing that it respects user privacy. Its privacy policy proudly states:
Following the Iranian elections (June 2009) many Iranian dissidents and protesters have switched to Yauba, according to the searchengine blog site, Pandia.
“Ahmed Hossain, CIO of Yauba, tells Pandia: “Our traffic from Iran has jumped 300% over the past several days, as many of them are using the Yauba Search Engine and the anonymity proxy filter to access blocked sites and get news from foreign sources.”
Anonymity may be important for some people. However for most, it’s search results that count. Although Yauba claims to be able to search semantically, differentiating between Java the island, Java the coffee and Java the computer language is this a meaningless boast?
In other words is Yauba worth using for those not looking to hide their identity.
The short answer is yes. Yauba searches various types of content – which are separated. As such it enables you to quickly find Acrobat files, Word documents, PowerPoint presentations, news, blogs, images, video, etc. in a single search. Each are kept distinct – and this is an interesting differentiator between it and other search engines. It also presents ways of refining queries and where there are alternative meanings it shows these – allowing users to pick the one they want.
Rather than use the search they suggest i.e. Java I put in Apple. The three meanings I thought of were
- The fruit
- The computer company
- The music company founded by the Beatles
In fact, there are several more – as Yauba shows:
apple can mean:
Apple Inc. (formerly Apple Computer, Inc.), a consumer electronics and software company Apple Bank, an American bank in the New York City area Apple Corps, a multimedia corporation founded by The Beatles Apple (album), an album by Mother Love Bone Apple (band), a British psychedelic rock band Apple Records, record label founded by The Beatles Apple I, Apple II series, Apple III, etc., various personal computer models produced by Apple, Inc and sold from 1976 until 1992. Ariane Passenger Payload Experiment, an Indian experimental communication satellite launched in 1981 Apple (automobile), an American automobile manufactured by Apple Automobile Company from 1917 to 1918 Billy Apple, artist Fiona Apple, a Grammy award winning American singer-songwriter R. W. Apple, Jr., an associate editor at The New York Times
Clicking on Apple (automobile) gives a number of results – not all directly relevant but some which were. There is also a brief encyclopedia type entry at the top of the page:
The Apple was a short-lived American automobile manufactured by Apple Automobile Company in Dayton, Ohio from 1917 to 1918. Agents were assured that its $1150 Apple 8 model was “a car which you can sell!”. Sadly for the company, it would seem that the public did not buy.

On the right of the screen are various suggestions for alternative searches. For example, a search for apple gives:
Compare the clarity of this to the same search on google. (Admitedly the search is not sophisticated and a competent searcher would refine the term – but for testing, it’s good enough)
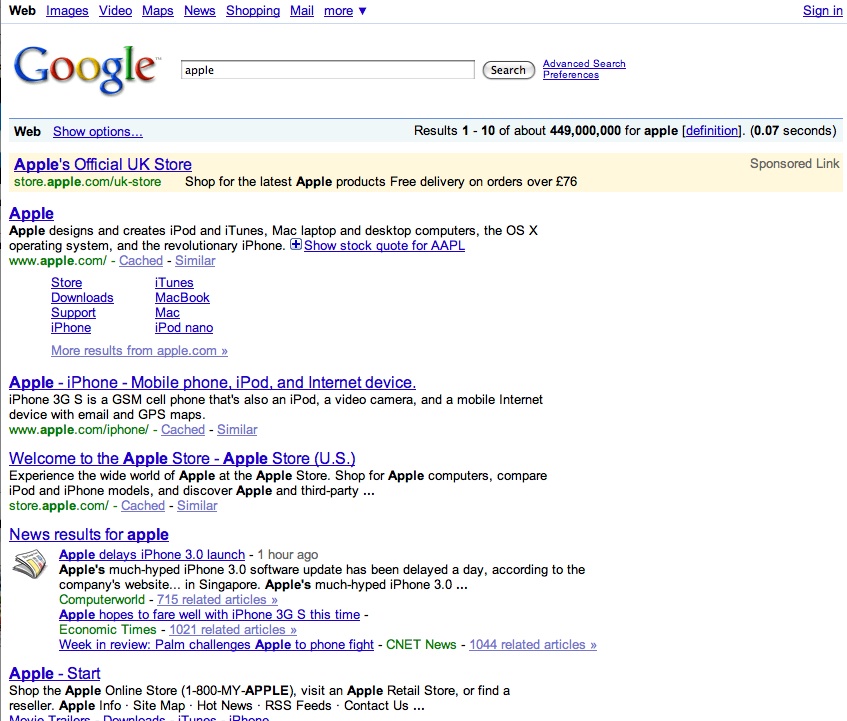
It means that amateur searchers are more likely to find resuls for complex searches – fulfilling Yauba’s claim to allow people to search without a knowledge of Boolean logic.
Also interesting is that a component of each search includes a real-time element – from Twitter and social news from Digg. The real time search element is useful as it provides another option to scoopler.
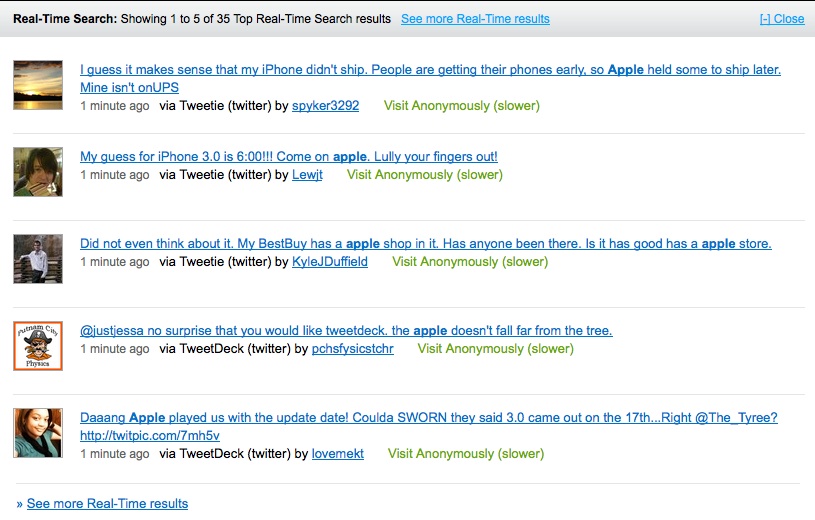
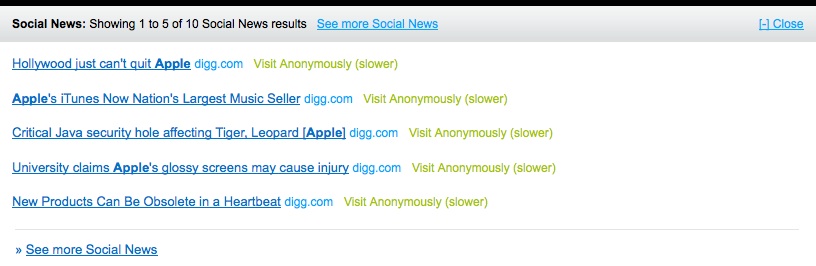
Sponsored ads appear to come from the Google network. There are also options to filter searches (although there is currently no information on what is being filtered) and a Lite version which seems to remove the refinement options and the top-level definitions (i.e. making it more Google like in its results presentation).
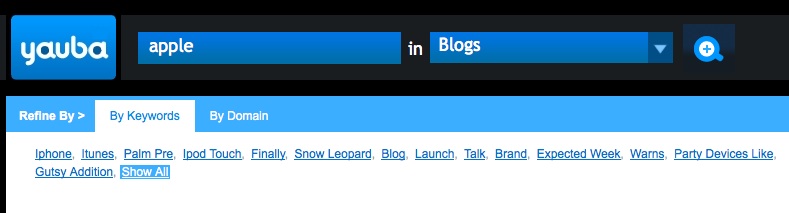
There is also an option to refine searches – alongside the search box.
 Selection of one of the options allows further search refinement either by keyword
Selection of one of the options allows further search refinement either by keyword
 or domain
or domain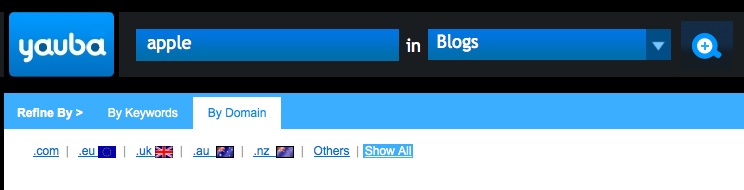
Overall I like Yauba. The interface is clean (and the black background makes a change from competitors).
Currently the site says it’s only an early Beta / Late Alpha preview release so more work / changes can be expected. Hopefully these will include Help files explaining what the Lite search is supposed to do and what a Filtered search actually filters. Also, what syntax is acceptable – to refine searches. Does Boolean searching actually work, for example? On my brief tests it seemed to – as did phrase searching i.e. putting search terms in quotes. What about other options – could any of the advanced search options from Exalead be included. And will the site cover more countries, than the current small number (Italy, France, UK, India, Brazil, Russia and the .com site)? Yauba promises to cover more countries – I’m just surprised that there is no Chinese or German version as I would have expected these before the Italian version. I guess the Yauba team have Italian speakers but currently no Chinese speakers.

Go to AWARE's web-site





 Competitive Intelligence News
Competitive Intelligence News
- An error has occurred; the feed is probably down. Try again later.
