Archive
Zanran – a new data search engine
I’ve been playing with a new data search engine called Zanran – that focuses on finding numerical and graphical data. The site is in an early beta. Nevertheless my initial tests brought up material that would only have been found using an advanced search on Google – if you were lucky. As such, Zanran promises to be a great addition for advanced data searching.

Zanran.com - Front Page
Zanran focuses on finding what it calls ‘semi-structured’ data on the web. This is defined as numerical data presented as graphs, tables and charts – and these could be held in a graph image or table in an HTML file, as part of a PDF report, or in an Excel spreadsheet. This is the key differentiator – essentially, Zanran is not looking for text but for formatted numerical data.
When I first started looking at the site I was expecting something similar to Wolfram Alpha – or perhaps something from Google (e.g. Google Squared or Google Public Data). Zanran is nothing like these – and so brings something new to search. Rather than take data and structure or tabulate it (as with Wolfram Alpha and Google Squared), Zanran searches for data that is already in tables or charts and uses this in its results listing.

Zanran.com Search: "Average Marriage Age"
The site has a nice touch in that hovering the cursor over results gives you the relevant data page – whether a table, a chart or a mix of text, tables or charts.

Zanran.com - Hovering over a result brings up an image of the data.
The advanced search options allow country searching (based on server location), document date and file type, each selectable from a drop-down box, as well as searches on specified web-sites. At the moment only English speaking countries can be selected (Australia, Canada, Ireland, India, UK New Zealand, USA and South Africa). The date selections allow for the last 6, 12 or 24 months and the file type allows for selection based on PDF; Excel; images in HTML files; tables in HTML files; PDF, Excel and dynamic data; and dynamic data alone. PowerPoint and Word files are promised as future options. There are currently no field search options (e.g. title searches).
My main dislike was that the site doesn’t give the full URLs for the data presented. The top-level domain is given, but not the actual URL which makes the site difficult to use when full attribution is required for any data found (especially if data gets downloaded, rather than opening up in a new page or tab).
Zanran.com has been in development since at least 2009 when it was a finalist in the London Technology Fund Competition. The technology behind Zanran is patented and based on open-source software, and cloud storage. Rather than searching for text, Zanran searches for numerical content, and then classifies it by whether it’s a table or a chart.
Atypically, Zanran is not a Californian Silicon Valley Startup, but is based in the Islington area of London, in a quiet residential side-street made up of a mixture of small mostly home-based businesses and flats/apartments. Zanran was founded by two chemists, Jonathan Goldhill and Yves Dassas, who had previously run telecom businesses (High Track Communications Ltd and Bikebug Radio Technologies) from the same address. Funding has come from the London Development Agency and First Capital among other investors.
Zanran views competitors as Wolfram Alpha, Google Public Data and also Infochimps (a database repository – enabling users to search for and download a wide variety of databases). The competitor list comes from Google’s cache of Zanran’s Wikipedia page as unfortunately, Wikipedia has deleted the actual page – claiming that the site is “too new to know if it will or will not ever be notable“.

Google Cache of Zanran's Wikipedia entry
I hope that Wikipedia is wrong and that Zanran will become “notable” as I think the company offers a new approach to searching the web for data. It will never replace Google or Bing – but that’s not its aim. Zanran aims to be a niche tool that will probably only ever be used by search experts. However as such, it deserves a chance, and if its revenue model (I’m assuming that there is one) works, it deserves success.
But it’s not google – Bing goes Live!
Another long wait between entries – I really must update more often. However recent events in the Search world and in the CI world mean I have no choice but to update. My thoughts on recent changes at SCIP will have to wait till my next post. This post will look at Microsoft‘s replacement for Live and MSN Search – with its new Bing search engine.
Searches at Live or MSN Search now redirect to Bing.com. I like the front-end – it’s clean and colourful. However I couldn’t find anywhere to change the front image – at least on the UK version that’s still in Beta. The US version does allow you to scroll back to previous images – with a little arrow option at the bottom of the right side of the screen.
The US version does allow you to scroll back to previous images – with a little arrow option at the bottom of the right side of the screen.
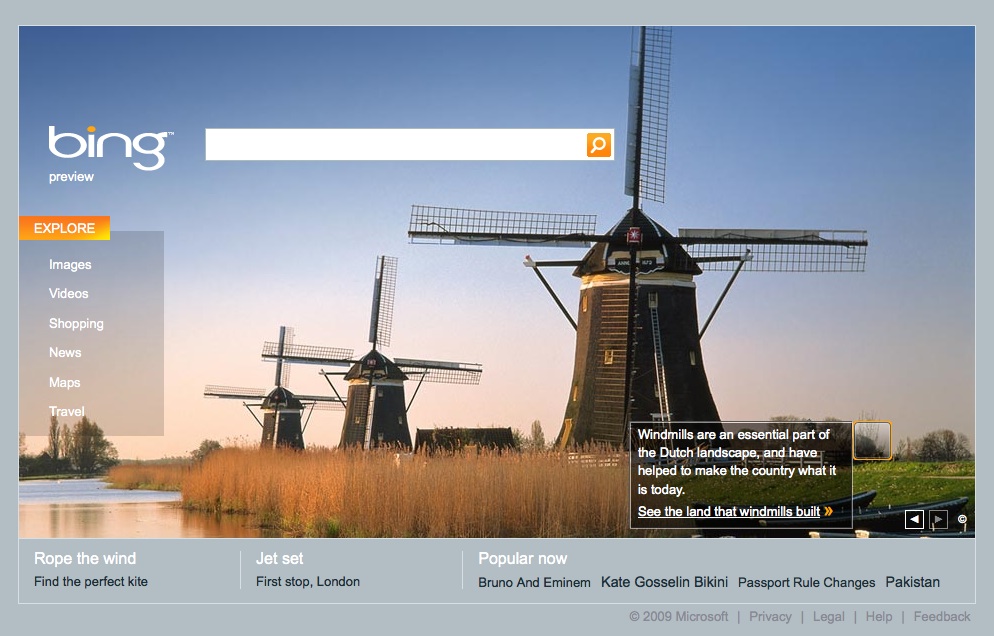
 The US version also includes hot-spots describing aspects of the picture, plus a side-bar offering more search options.
The US version also includes hot-spots describing aspects of the picture, plus a side-bar offering more search options.
At the bottom of both versions is a link for help – interestingly still pointing to Live.com. Obviously Microsoft still has more work to do on this. The help section gives the format for advanced commands and also allows you to remove the screen background.
So how does Bing perform. For the searches I tried, the results are good – and there isn’t that much to choose between Google and Bing. One difference i did notice is that URLs with the search terms used seem to come higher than other sites – so, for example, AWARE‘s web-site came to the top for a search on “marketing-intelligence“. Also relevant is that the algorithm is sufficiently intelligent to realise that “CompetitorAnalysis.com” is a likely candidate for searches on “Competitor Analysis“. I’m not sure the same precision exists in Google. Another odd feature is that some titles seem to be edited. For example some searches on my web-site content bring up the following title: “
This title doesn’t exist on our web-site so has been taken from somewhere else – most likely from a link on a UK government business support web-site.
Where Bing falls is in the advanced searching and also the preferences. I like that you can set Google to display 100 hits at a time. Bing only allows 50. Bing also lacks some of the field / advanced search options available to Google. There are no wild-card searches (using the * character) or synonym searches (the ~ character) for example. However there are options that are not currently available in Google – such as the feed:, hasfeed:, loc:, and contains: options. These allow for searching for RSS sites (feed: and hasfeed:), location searches (loc:), searches for sites containing links to types of content such as WMA, MPG files, etc. – contains:. These options are not available in the advanced search boxes.
All in all – i like Bing and prefer its interface to Live. I like colourful pages, and have customised my Google page with iGoogle themes, and Ask with it’s skins. Yet again, however, this is not a Google Killer – and perhaps it’s not trying to be. The key thing: Bing is not google!
A number of other reviews on Bing worth reading:
Mixed reviews of Bing, Microsoft’s new search engine – the Daily Telegraph
Bing Don’t Bother – Karen Blakeman’s review
Bing Launches – it’s awful – Phil Bradley’s review
Bing Bing: Microsoft’s search engine unexpectedly live, but not Live – the Guardian

Go to AWARE's web-site





 Competitive Intelligence News
Competitive Intelligence News
- An error has occurred; the feed is probably down. Try again later.
